
How Google Determines Actual CPCs Will Surprise You
OK, so you’ve been investing in PPC advertising for years. You know how your KPIs are performing, and how much you’re spending each month. Your in-house team or agency reports back to you on overall performance and dazzles you with insightful and actionable analyses each week. You feel very comfortable with their PPC knowledge and then one day you ask one of the most basic PPC questions: how are CPCs in AdWords calculated? Their response is questionable at best, and you start to think their so-called “expertise” is a sham. They should be able to easily answer this question, right?
Well, before you judge your team too harshly, let us walk you through how CPCs are actually determined and why it’s not a question so easily answered.
How Are CPCs Actually Calculated?
Before we get into the specific calculations, we need to first talk about the AdWords auction and what influences your CPC, position and impression share, since these three metrics are all related. All three metrics are determined by your Ad Rank, a metric that includes your Quality Score, maximum CPC and expected impact of ad formats. The advertiser that shows in position 1 (“Advertiser 1”) is the advertiser whose combination of Quality Score, expected impact of ad formats and maximum CPC is highest. Google first determines the position for each advertiser, and then calculates the actual CPC for each advertiser based on that position.
To really see how this plays out, let’s look at an example:
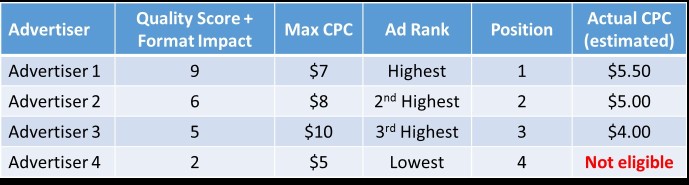
In the chart above, Advertiser 1 will show in position 1 because they have the highest Ad Rank. Once position is determined, the AdWords system then determines the actual CPC that advertiser will pay. Keep in mind that the idea that each advertiser only pays $0.01 more than the next advertiser no longer applies (unless all advertisers have the exact same Quality Score and Format Impact). In fact, it is entirely possible for an advertiser in position 2 to pay a higher CPC than the advertiser in position 1. Advertiser 1’s actual CPC is the lowest amount they can pay while still achieving an Ad Rank higher than Advertiser 2. The CPCs for the other advertisers are calculated using the same logic. Since Advertiser 4 has by far the lowest Quality Score and max CPC, they are likely to be ineligible to show or have extremely limited impression share.
How Can I Use CPC Calculations to My Benefit?
Now that we know how CPCs are determined, how can this help you improve your performance? First of all, keep in mind that ad extensions do play a role in determining your Quality Score, and Google is introducing new ad extensions all the time (they just recently announced structured snippets, for example). You should be using as many ad extensions as reasonably possible, and optimizing your ad extensions at least as often as you’re updating your main ad copy. This will help improve Quality Score, which can help reduce your CPCs and/or improve your position.
Also, this may be obvious, but you should be making regular ad copy testing a top priority. With expected click-through rate and ad relevance accounting for a majority of your Quality Score, it’s critical that you’re using relevant headlines and descriptions that are truly differentiated from your competition and highly enticing to your audience.
Lastly, keep in mind that it’s extremely difficult to run PPC ads profitably with low Quality Scores. Constantly inflating your max CPCs to drive impression share and high positions is not a sustainable strategy. Other advertisers are typically setting their bids to meet profitability, and if they’re showing more often and more prominently, it likely means they have higher Quality Scores. If you end up paying significantly more per click, you should have a strong business case for doing so (e.g. significantly higher conversion rates, better lead close rates, higher customer lifetime value, etc.). You should also continually focus on ad improvements and ensure a relevant landing page experience. The steady, consistent path of testing and analysis (in replace of or in addition to aggressive bid increases) will help you to maintain efficiency as you expand and as competition increases.
If you’re interested in learning more about how CPCs are calculated, see a great video by Google’s chief economist, Hal Varian, or check out these two articles that cover CPCs for the Search network and CPCs for the Display network.
If you’d like to learn more about Synapse SEM, please complete our contact form or call us at 781-591-0752.



